A lookup table is a specific type of context in Tenzir’s enrichment framework. It has “two ends” in that you can use pipelines to update it, as well as pipelines to perform lookups and attach the results to events. Lookup tables live in a node and multiple pipelines can safely use the same lookup table. All update operations propagate to disk, persisting the changes and making them resilient against node restarts.
Lookup tables are particularly powerful for:
- Threat Intelligence: Track indicators of compromise (IoCs) like malicious domains, IPs, or file hashes.
- Asset Inventory: Map IP addresses or subnets to organizational data.
- Entity Tracking: Build passive DNS tables or track user-to-host mappings.
- Dynamic Enrichment: Update context in real-time as your environment changes.
Create a lookup table
Section titled “Create a lookup table”You can create a lookup table with the
context::create_lookup_table
operator as a pipeline, or interactively in the platform.
Create a lookup table from a pipeline
Section titled “Create a lookup table from a pipeline”The context::create_lookup_table
operator creates a new, empty lookup table:
context::create_lookup_table "my_lookup_table"Create a lookup table as code
Section titled “Create a lookup table as code”You can also create a lookup table as code by adding it to tenzir.contexts in
your tenzir.yaml configuration file:
tenzir: contexts: my-lookup-table: type: lookup-tableThis approach is useful for:
- Infrastructure as Code: Define lookup tables in version control
- Automated Deployments: Ensure lookup tables exist on node startup
- Consistent Environments: Replicate the same contexts across multiple nodes
Create a lookup table in the platform
Section titled “Create a lookup table in the platform”The following steps
-
In the Contexts tab in your node, click the
+button:
-
Select type
lookup-tableand enter a name: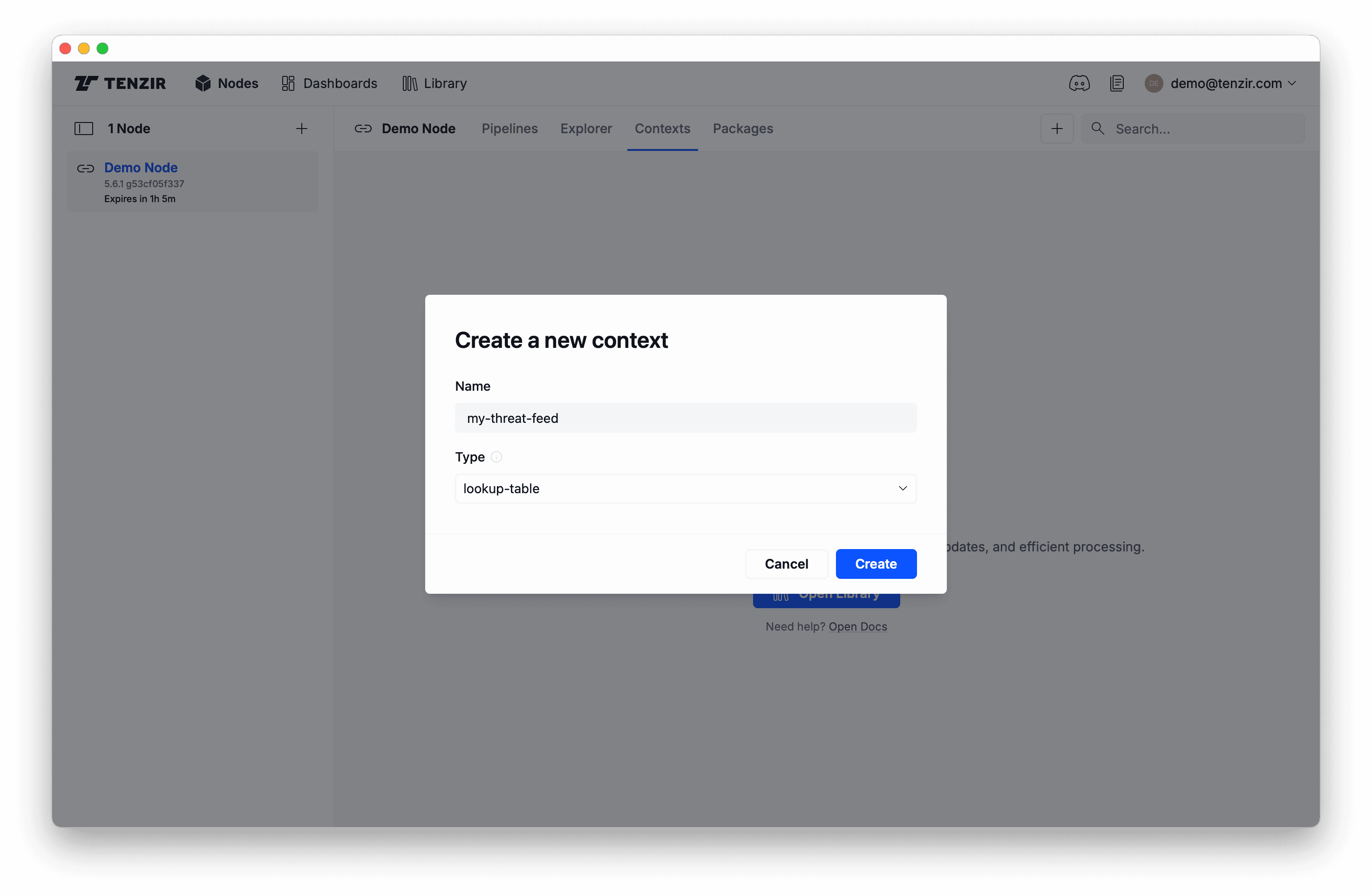
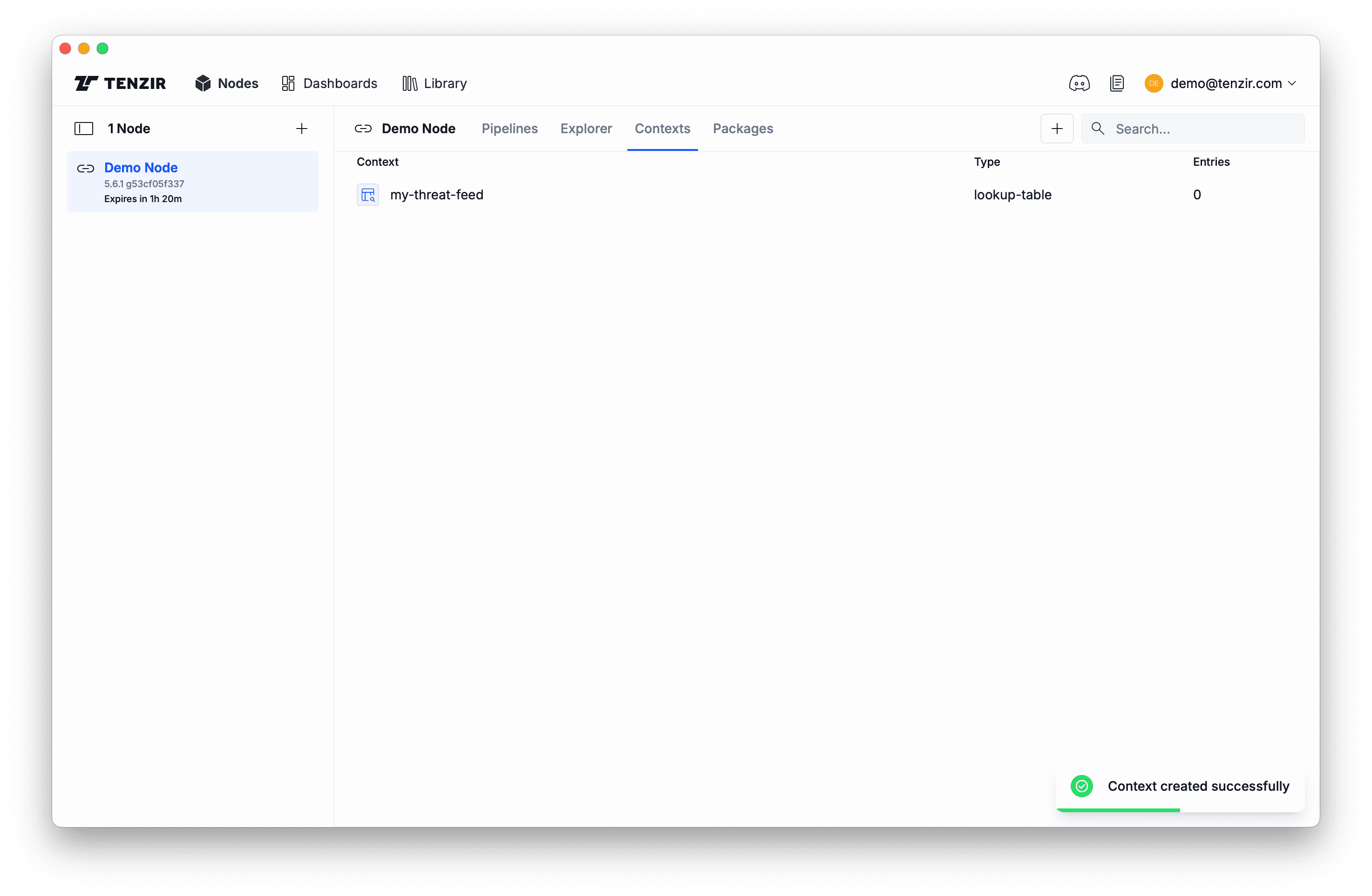
-
Click Create and observe the new lookup table context:
Show all available lookup tables
Section titled “Show all available lookup tables”Use the context::list operator to
retrieve all contexts in your node:
context::listThis shows all contexts including lookup tables, bloom filters, and GeoIP databases. Here’s an example output after creating different context types:
// First, create some contexts.context::create_lookup_table "threat_intel"context::create_bloom_filter "malware_hashes", capacity=1M, fp_probability=0.01Now list them.
context::list{ num_entries: 0, name: "threat_intel", configured: false}{ num_elements: 0, parameters: {m: 9585058, n: 1000000, p: 0.01, k: 7}, name: "malware_hashes", configured: false}{ name: "geo", type: "geoip"}Filter the results to find specific contexts:
context::listwhere name.match_regex("[T|t]hreat")Delete a lookup table
Section titled “Delete a lookup table”Use the context::remove operator to
delete a lookup table:
context::remove "my_lookup_table"This permanently deletes the specified lookup table and its persisted data.
Perform lookups
Section titled “Perform lookups”Use the context::enrich operator to
enrich events with data from a lookup table.
Perform a point lookup
Section titled “Perform a point lookup”First, create a simple lookup table:
context::create_lookup_table "user_roles"Populate it with data:
from {user_id: 1001, role: "admin", department: "IT"}, {user_id: 1002, role: "analyst", department: "Security"}, {user_id: 1003, role: "engineer", department: "DevOps"}context::update "user_roles", key=user_idNow enrich events with this lookup table:
from {user_id: 1002, action: "login", timestamp: 2024-01-15T10:30:00}context::enrich "user_roles", key=user_id{ user_id: 1002, action: "login", timestamp: 2024-01-15T10:30:00, user_roles: { user_id: 1002, role: "analyst", department: "Security" }}Specify where to place the enrichment:
from {user_id: 1002, action: "login"}context::enrich "user_roles", key=user_id, into=user_info{ user_id: 1002, action: "login", user_info: { user_id: 1002, role: "analyst", department: "Security" }}Use OCSF format for standardized enrichment:
from {user_id: 1002, action: "login"}context::enrich "user_roles", key=user_id, format="ocsf"{ user_id: 1002, action: "login", user_roles: { created_time: 2024-11-18T16:35:48.069981, name: "user_id", value: 1002, data: { user_id: 1002, role: "analyst", department: "Security" } }}Perform a subnet lookup with an IP address key
Section titled “Perform a subnet lookup with an IP address key”When lookup table keys are of type subnet, you can probe the table with ip
values. The lookup performs a longest-prefix match, perfect for network
inventory and CMDB use cases:
context::create_lookup_table "network_inventory"Populate with network infrastructure data:
from {subnet: 10.0.0.0/22, owner: "IT", location: "Datacenter-A"}, {subnet: 10.0.0.0/24, owner: "IT-Web", location: "Datacenter-A"}, {subnet: 10.0.1.0/24, owner: "IT-DB", location: "Datacenter-A"}, {subnet: 10.0.2.0/24, owner: "Dev", location: "Office-B"}, {subnet: 192.168.0.0/16, owner: "Guest", location: "All"}context::update "network_inventory", key=subnetNow enrich network traffic with infrastructure context:
from { timestamp: 2024-01-15T14:23:45, src_ip: 10.0.0.15, dst_ip: 10.0.1.20, bytes: 1048576, proto: "tcp"}context::enrich "network_inventory", key=src_ip, into=src_networkcontext::enrich "network_inventory", key=dst_ip, into=dst_network{ timestamp: 2024-01-15T14:23:45, src_ip: 10.0.0.15, dst_ip: 10.0.1.20, bytes: 1048576, proto: "tcp", src_network: { subnet: 10.0.0.0/24, owner: "IT-Web", location: "Datacenter-A" }, dst_network: { subnet: 10.0.1.0/24, owner: "IT-DB", location: "Datacenter-A" }}The IP 10.0.0.15 matches 10.0.0.0/24 (Web frontends) rather than
10.0.0.0/22 because /24 is a longer (more specific) prefix match.
Perform a lookup with compound key
Section titled “Perform a lookup with compound key”Use record types as compound keys for complex matching scenarios.
context::create_lookup_table "threat_intel"Populate a table with a compound key:
from { threat_id: "APT-2024-001", indicators: { domain: "malicious.example.com", port: 443 }, severity: "critical", campaign: "DarkStorm", first_seen: 2024-01-10T00:00:00}context::update "threat_intel", key=indicatorsPick a compound key for the table lookup:
from { timestamp: 2024-01-15T10:30:00, dest_domain: "malicious.example.com", dest_port: 443, src_ip: "10.0.1.50"}context::enrich "threat_intel", key={domain: dest_domain, port: dest_port}, into=threat_infoImplement zone-based access control using compound keys:
context::create_lookup_table "access_rules"Define rules for zone pairs:
from ( { key: {source_zone: "internet", dest_zone: "dmz"}, action: "allow", log: true }, { key: {source_zone: "internet", dest_zone: "internal"}, action: "deny", log: true, alert: true })context::update "access_rules", key=key, value=thisCheck access for firewall events:
from { timestamp: 2024-01-15T10:30:00, source_zone: "internet", dest_zone: "internal", src_ip: "203.0.113.10", dst_ip: "10.0.1.50"}context::enrich "access_rules", key={source_zone: source_zone, dest_zone: dest_zone}, into=policyCompound keys enable sophisticated matching based on multiple fields.
Add/overwrite entries in lookup table
Section titled “Add/overwrite entries in lookup table”Use the context::update operator to
add or update entries. This is ideal for maintaining dynamic threat
intelligence or asset inventory:
Update threat intelligence from an API:
from_http "https://threatfox-api.abuse.ch/api/v1/", body={query: "get_iocs", days: 1} { read_json}unroll datawhere data.ioc_type == "domain"context::update "threatfox", key=ioc, value=dataTrack user login statistics:
from { user: "alice@company.com", login_time: 2024-01-15T09:00:00, source_ip: "10.0.50.100", success: true}context::update "user_logins", key=user, value={ last_login: login_time, last_ip: source_ip, status: if success then "active" else "failed"}Associate timeouts with entries
Section titled “Associate timeouts with entries”Timeouts are essential for managing the lifecycle of threat intelligence and
maintaining fresh context. You can set expiration timeouts on lookup table
entries using the context::update
operator:
Most IoCs have a short half-life. Automatically expire stale entries:
from_file "threat_feed.json" { read_json}where confidence_score >= 70context::update "active_threats", key=indicator, value={ threat_type: threat_type, severity: severity, source: "ThreatFeed-Premium" }, create_timeout=7d, // Remove after 7 days regardless write_timeout=72h // Remove if not updated for 3 daysTrack sessions with activity-based expiration:
from { session_id: "sess_abc123", user: "alice@company.com", login_time: 2024-01-15T09:00:00, ip: "10.0.50.100"}context::update "active_sessions", key=session_id, write_timeout=30min, // Session expires after 30 min of inactivity read_timeout=30min // Also expire if not accessed for 30 minTrack DHCP leases with automatic expiration:
from { mac: "00:11:22:33:44:55", ip: "10.0.100.50", hostname: "laptop-alice", lease_time: 2024-01-15T10:00:00}context::update "dhcp_leases", key=mac, value={ip: ip, hostname: hostname, assigned: lease_time}, create_timeout=4h // DHCP lease durationImplement API rate limiting with sliding windows:
from {api_key: "key_123", request_time: now()}context::update "api_rate_limits", key=api_key, value={request_count: count()}, create_timeout=1h, // Reset counter every hour write_timeout=1h // Also reset if no requests for 1 hourThe three timeout types work together:
create_timeout: Hard expiration - useful for data with known shelf lifewrite_timeout: Expire stale data - useful for removing inactive entriesread_timeout: Expire unused data - useful for caching scenarios
Remove entries from a lookup table
Section titled “Remove entries from a lookup table”Use the context::erase operator to
remove specific entries, useful for allowlisting, removing false positives, or
cleaning up outdated data:
Remove false positives from threat intelligence:
from {indicator: "legitimate-site.com", reason: "false_positive"}context::erase "threat_indicators", key=indicatorRemove IPs from blocklist after remediation:
from_file "remediated_hosts.csv" { read_csv}where remediation_confirmed == truecontext::erase "compromised_hosts", key=ip_addressClean up old sessions on logout:
from { event_type: "logout", session_id: "sess_xyz789", user: "alice@company.com", timestamp: 2024-01-15T17:00:00}where event_type == "logout"context::erase "active_sessions", key=session_idRemove all entries older than 30 days from a context:
context::inspect "temp_indicators"where first_seen > now() - 30dcontext::erase "temp_indicators", key=indicatorShow entries in a lookup table
Section titled “Show entries in a lookup table”Use the context::inspect operator to
view and analyze the contents of a lookup table:
// View all entriescontext::inspect "threat_indicators"{ key: "malicious.site.com", value: { threat_type: "phishing", first_seen: 2024-01-10T08:00:00, last_seen: 2024-01-15T14:30:00, severity: "high", source: "PhishTank" }}Analyze lookup table contents:
context::inspect "network_inventory"top subnetFind specific entries:
context::inspect "user_sessions"where key.user == "alice@company.com"Export data for reporting:
context::inspect "asset_inventory"select asset_id=key, value.owner, value.department, value.last_seento "asset_report.csv"Check table size and find old entries:
context::inspect "passive_dns"set age = now() - value.last_seenwhere age > 7dsummarize old_entries=count(){ old_entries: 42}Update lookup tables from APIs
Section titled “Update lookup tables from APIs”Periodically poll APIs to maintain fresh reference data, threat intelligence, or asset information in lookup tables.
Basic periodic updates
Section titled “Basic periodic updates”Use the every operator to schedule regular API
polls that update a lookup table:
every 1h { from_http "https://threatfeed.example.com/api/v1/indicators"}where confidence >= 80context::update "threat_indicators", key=indicator, value=metadataUpdate with expiration
Section titled “Update with expiration”Combine periodic updates with timeouts to automatically remove stale entries:
every 30min { from_http "https://dns-blocklist.example.com/domains.json"}unroll domainscontext::update "blocklist", key=domains.domain, value={ category: domains.category, severity: domains.severity, last_updated: now() }, create_timeout=24h, // Remove after 24 hours write_timeout=2h // Remove if not updated for 2 hoursExport and import lookup table state
Section titled “Export and import lookup table state”Export lookup table state
Section titled “Export lookup table state”Use the context::save operator to create
backups or migrate lookup tables between nodes:
Backup critical threat intelligence:
context::save "threat_indicators"save_file "threat_intel_backup_2024_01_15.bin"Export for migration to another node:
context::save "network_inventory"save_file "network_inventory_prod.bin"Automated daily backup:
every 1d { context::save "asset_tracking" save_file f"backups/assets_{now().format('%Y%m%d')}.bin"}Import lookup table state
Section titled “Import lookup table state”Use the context::load operator to
restore lookup tables from backups or migrate data:
from_file "threat_intel_backup_2024_01_15.bin"context::load "threat_indicators"Best Practices
Section titled “Best Practices”- Design efficient keys: Use the most selective field as the key to minimize table size
- Set appropriate timeouts: Base timeouts on data freshness requirements to prevent unbounded growth
- Monitor table size: Regularly inspect tables to prevent excessive growth
- Backup critical contexts: Schedule regular exports of important tables
- Test enrichments: Verify logic with
context::inspectbefore production deployment