We are thrilled to announce Tenzir
v4.12, a feature-packed
release introducing numerous enhancements. Notable additions include list
unrolling, event deduplication, and the deployment of advanced pipeline
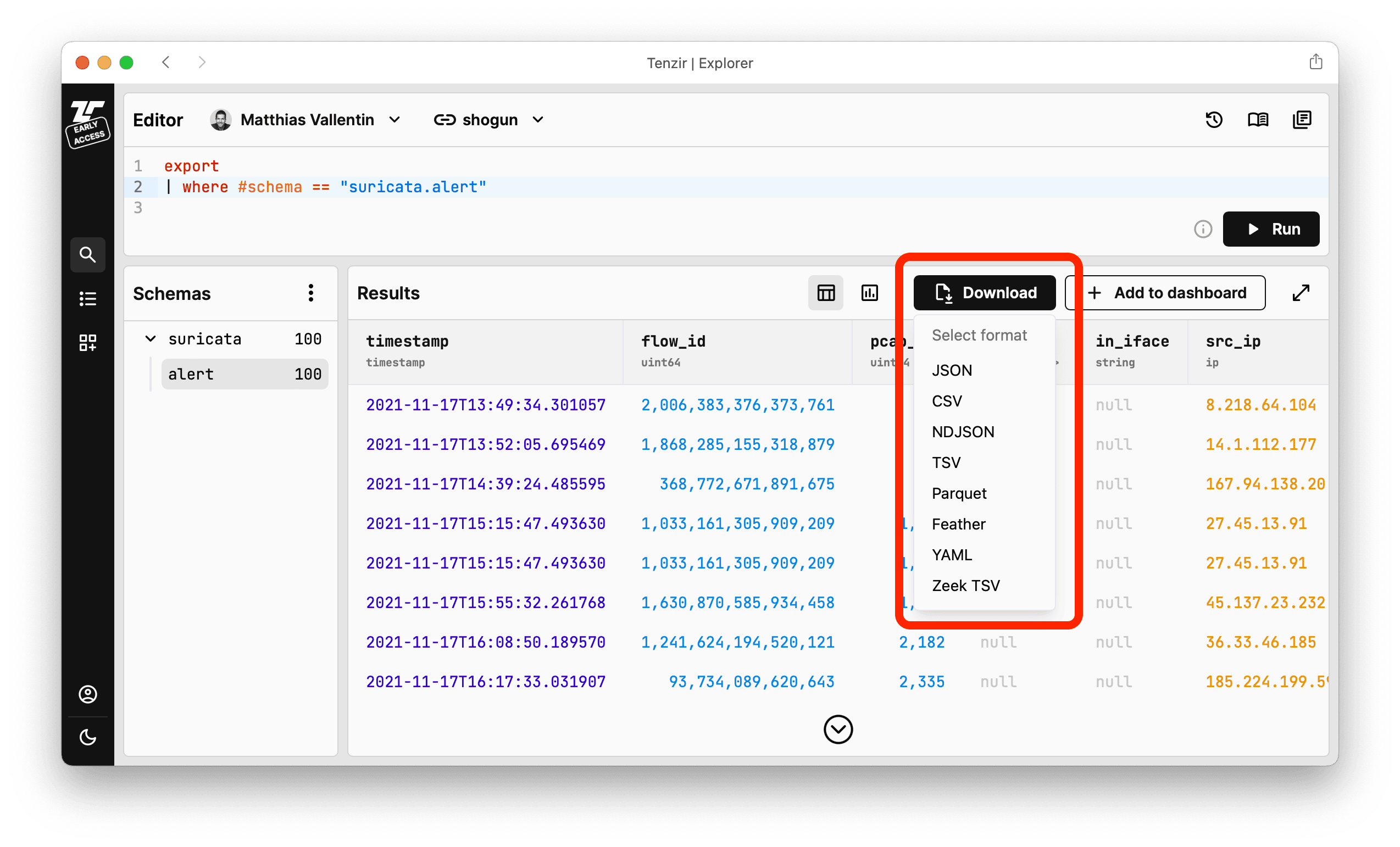
architectures with publish-subscribe. We've also added a download button,
extended support for UDP, and implemented many other refinements to improve your
experience.
In today's data-driven world, many data sources deliver information in the form
of lists/arrays. While seemingly simple, working with these lists can sometimes
pose challenges, particularly when the data structure becomes intricate. Let's
take the example of a connection summary stream in JSON format:
To overcome the hurdles of JSON list manipulation, we introduce the new
unroll operator, allowing the creation of an event for each item in the list.
Let's unroll dst:
The data is now significantly easier to work with.
Do you see the duplicate host pairs? Let's remove them with the new
deduplicate operator. Run deduplicate src, dst --timeout 24h to condense the
above output to:
The --timeout option is useful for controlling expiration of entries. In this
example, if the same connection tuple doesn't come up within a 24h interval, the
corresponding entry is removed from the operator's internal state.
We delved deeper into the power of the deduplicate operator in a previous
blog post.
Building on this, the every operator (prominently featured in the previous
release) can now also accompany
transformations and sinks. To illustrate, let's answer this question: "With how
many new destinations did each device communicate in the last minute?"
Using every 1min summarize num=count(.) by src, we get:
{"src": "192.0.2.1", "num": 2}// after 1min:{"src": "192.0.2.1", "num": 1}
In summary, these transformations provide powerful in-band capabilities leading
to substantial data reduction, simplifying the analysis, and making data shaping
more efficient.
Exciting are also the new publish and subscribe operators, which open up
endless possibilities for creating arbitrary dataflow topologies. For instance,
you can set a publishing point within your data stream. It's as simple as from
tcp://0.0.0.0:8000 | publish input. This defines a channel input that you can
now subscribe to with subscribe.
Let's consider a case where we aim to route all alerts into Splunk, and
concurrently import all other non-alert events into Tenzir's storage for further
analysis and monitoring:
subscribe input| where alert == true| to splunk
subscribe input| where alert == false| import
Here, the first subscriber takes the events from the input channel where the
alert field is true and routes them to Splunk. In parallel, the second
subscriber takes the remaining events with the alert field marked as false and
imports them into Tenzir’s storage. Our new feature enables this precise,
dynamic routing, making data management more efficient and streamlined.
Tenzir v4.10 introduced introduced the ability to statically
define pipelines in Tenzir's configuration file: Pipelines as Code (PaC).
This release expands upon that capability by also allowing static configuration
of contexts.
tenzir.yaml
tenzir: contexts: # A unique name for the context that's used in the context, enrich, and # lookup operators to refer to the context. indicators: # The type of the context (e.g., `lookup-table`, `geoip`, ...). type: bloom-filter # Arguments for creating the context, as described by the documentation of # the chosen context type. arguments: capacity: 1B fp-probability: 0.001
On a related note: The operators context create, context reset,
context update, and context load were changed to no longer return
information about the associated context. Instead, they now act as a sink.
There's a new udp connector for sending and receiving UDP datagrams.
Finally, you can now receive Syslog natively.
Speaking of Syslog: we've enhanced our parser to be multi-line. In case the
next line isn't a valid Syslog message by itself, we interpret it as the
continuation of the previous message.
The tcp loader now accepts multiple connections in parallel, e.g., when used
as from tcp://127.0.0.1:8000 read json.
We've massively improved performance of our Parquet and Feather formats for
large files. For writing, they now both support streaming row groups and
record batches, respectively, and for reading Feather now supports streaming
via the Arrow IPC format as well. This comes in handy for those of you working
in the Apache Arrow ecosystem and seeking seamless interoperability without
loss of rich typing.
As usual, the complete list of bug fixes, adjustments, and enhancements
delivered with this version can be found in our changelog.