
Dear community, we are excited to announce VAST v2.0, bringing faster execution of bulk-submitted queries, improved tunability of index structures, and new configurability through environment variables.
Query Scheduling
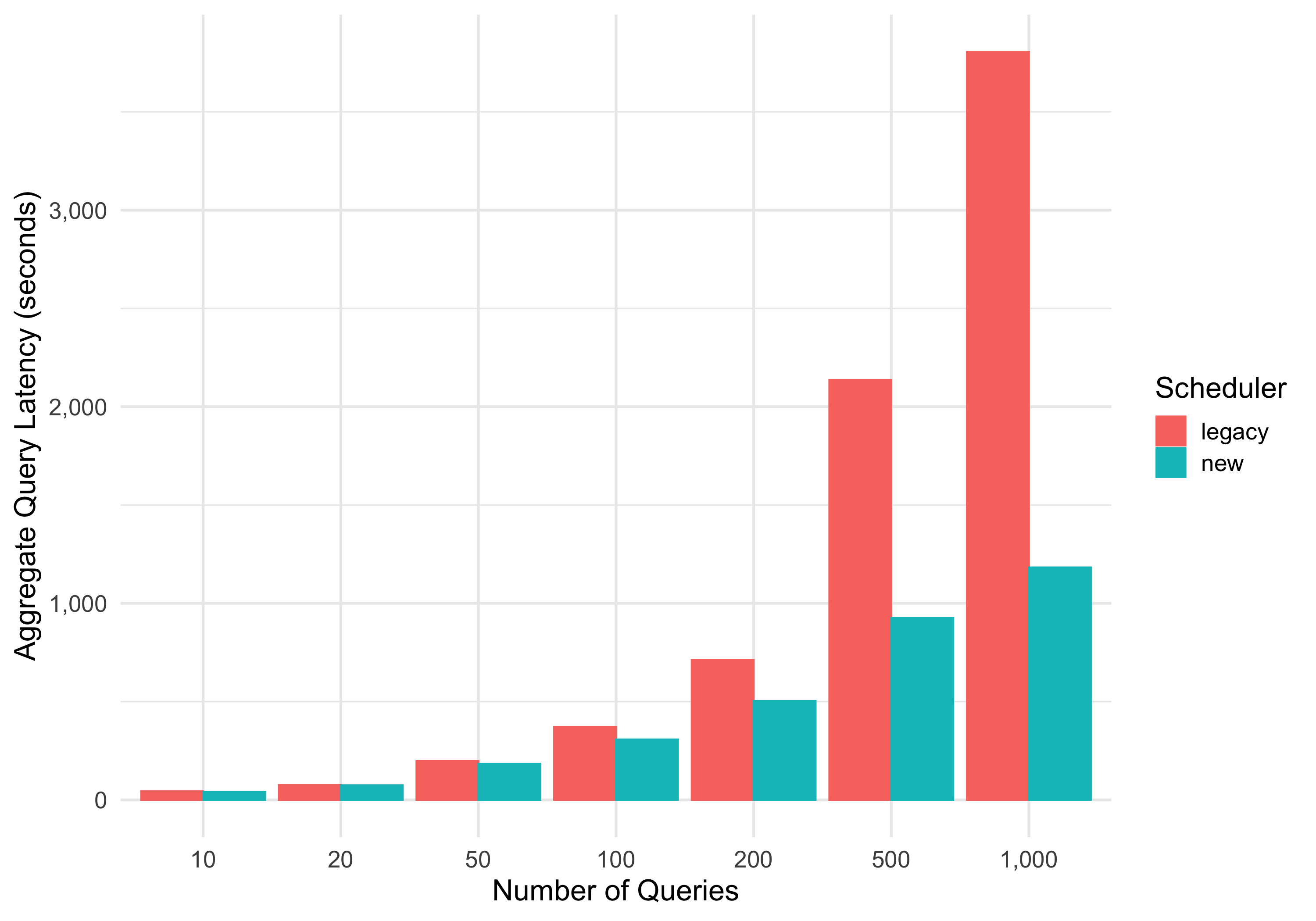
VAST is now more intelligent in how it schedules queries.
When a query arrives at the VAST server, VAST first goes to the catalog which returns a set of on-disk candidate partitions that the query may be applicable to. Previous versions of VAST simply iterated through the available queries as they came in, loading partition by partition to extract events. Due to memory constraints, VAST is only able to keep some partitions in memory, which causes frequent loading and unloading of the same partitions for queries that access the same data. Now, VAST loads partitions depending on how many queries they are relevant for and evaluates all ongoing queries for one partition at a time.
Additionally, VAST now partitions the data for each schema separately, moving away from partitions that contain events of multiple schemas. This helps with common access patterns and speeds up queries restricted to a single schema.
The numbers speak for themselves:
Updates to Aging, Compaction, and the Disk Monitor
VAST v1.0 deprecated the experimental aging feature. Given popular demand we've decided to un-deprecate it and to actually implement it on top of the same building blocks the new compaction mechanism uses, which means that it is now fully working and no longer considered experimental.
The compaction plugin is now able to apply general time-based compactions that are not restricted to a specific set of types. This makes it possible for operators to implement rules like "delete all data after 1 week", without having to list all possible data types that may occur.
Some smaller interface changes improve the observability of the compactor for
operators: The vast compaction status command prints the current compaction
status, and the vast compaction list command now lists all configured
compaction rules of the VAST node.
Additionally, we've improved overall stability and fault tolerance improvements surrounding the disk monitor and compaction features.
Fine-tuned Catalog Configuration
This section is for advanced users only.
The catalog manages partition metadata and is responsible for deciding whether a partition qualifies for a certain query. It does so by maintaining sketch data structures (e.g., Bloom filters, summary statistics) for each partition. Sketches are highly space-efficient at the cost of being probabilistic and yielding false positives.
Due to this characteristic, sketches can grow sublinear: doubling the number of events in a sketch does not lead to a doubling of the memory requirement. Because the catalog must be traversed in full for a given query it needs to be maintained in active memory to provide high responsiveness.
A false positive can have substantial impact on the query latency by materializing irrelevant partitions, which involves unnecessary I/O. Based on the cost of I/O, this penalty may be substantial. Conversely, reducing the false positive rate increases the memory consumption, leading to a higher resident set size and larger RAM requirements.
You can control this space-time trade-off in the configuration section
vast.index by specifying index rules. Each rule corresponds to one sketch and
consists of the following components:
targets: a list of extractors to describe the set of fields whose values to
add to the sketch. fp-rate: an optional value to control the false-positive
rate of the sketch.
VAST does not create field-level sketches unless a dedicated rule with a matching target configuration exists. Here's an example:
vast:
index:
rules:
- targets:
# field synopses: need to specify fully qualified field name
- suricata.http.http.url
fp-rate: 0.005
- targets:
- :ip
fp-rate: 0.1
This configuration includes two rules (= two sketches), where the first rule
includes a field extractor and the second a type extractor. The first rule
applies to a single field, suricata.http.http.url, and has a false-positive
rate of 0.5%. The second rule creates one sketch for all fields of type addr
that has a false-positive rate of 10%.
Configuring VAST with Environment Variables
VAST now offers an additional configuration path besides editing YAML configuration files and providing command line arguments: setting environment variables. This enables a convenient configuration experience when using container runtimes, such as Docker, where the other two configuration paths have a mediocre UX at best:
The container entry point is limited to adding command line arguments, where not all options may be set. For Docker Compose and Kubernetes, it is often not trivially possible to even add command line arguments.
Providing a manual configuration file is a heavy-weight action, because it requires (1) generating a potentially templated configuration file, and (2) mounting that file into a location where VAST would read it.
An environment variable has the form KEY=VALUE. VAST processes only
environment variables having the form VAST_{KEY}=VALUE. For example,
VAST_ENDPOINT=1.2.3.4 translates to the command line option
--endpoint=1.2.3.4 and YAML configuration vast.endpoint: 1.2.3.4.
Regarding precedence, environment variables override configuration file settings, and command line arguments override environment variables. Please consult the documentation for a more detailed explanation of how to specify keys and values.
VLAN Tag Extraction and Better Packet Decapsulation
VAST now extracts 802.1Q VLAN tags
from packets, making it possible to filter packets based on VLAN ID. The packet
schema includes a new nested record vlan with two fields: outer and inner
to represent the respective VLAN ID. For example, you can generate PCAP traces
of packets based on VLAN IDs as follows:
vast export pcap 'vlan.outer > 0 || vlan.inner in [1, 2, 3]' | tcpdump -r - -nl
VLAN tags occur in many variations, and VAST extracts them in case of single-tagging and QinQ double-tagging. Consult the PCAP documentation for details on this feature.
Internally, the packet decapsulation logic has been rewritten to follow a layered approach: frames, packets, and segments are the building blocks. The plan is to reuse this architecture when switching to kernel-bypass packet acquisition using DPDK. If you would like to see more work on the front of high-performance packet recording, please reach out.
Breaking Changes
The --verbosity command-line option is now called --console-verbosity. The
shorthand options -v, -vv, -vvv, -q, -qq, and -qqq are unchanged.
This aligns the command-line option with the configuration option
vast.console-verbosity, and disambiguates from the vast.file-verbosity
option.
The Meta Index is now called the Catalog. This affects multiple status and metrics keys. We plan to extend the functionality of the Catalog in a future release, turning it into a more powerful first instance for lookups.
Transform steps that add or modify columns now add or modify the columns in-place rather than at the end, preserving the nesting structure of the original data.
Changes for Developers
The vast get command no longer exists. The command allowed for retrieving
events by their internal unique ID, which we are looking to remove entirely in
the future.
Changes to the internal data representation of VAST require all transform step plugins to be updated. The output format of the vast export arrow command changed for the address, subnet, pattern, and enumeration types, which are now modeled as Arrow Extension Types. The record type is no longer flattened. The mapping of VAST types to Apache Arrow data types is now considered stable.
Smaller Things
- VAST client commands now start much faster and use less memory.
- The
vast count --estimate '<query>'feature no longer unnecessarily causes stores to load from disk, resulting in major speedups for larger databases and broad queries. - The tenzir/vast repository now contains experimental Terraform scripts for deploying VAST to AWS Fargate and Lambda.